ほとんどの場合、アクセスをブロックする必要がある場合 SeekportBot またはその他 crawl bots ウェブサイトの場合、理由は簡単です。 Web スパイダーは、短期間に非常に多くのアクセスを行い、Web サーバーのリソースを要求します。または、Web サイトをインデックスに登録したくない検索エンジンからアクセスします。
これは、c が訪問する Web サイトにとって非常に有益です。raw私は彼にぶつかった。 これらの Web スパイダーは、検索エンジンで Web ページのコンテンツを探索、処理、およびインデックス化するように設計されています。 Google と Bing はそのような c を使用します。raw私は彼にぶつかった。 ただし、ロボットを使用して Web ページからデータを収集する検索エンジンもあります。 Seekport これらの検索エンジンの XNUMX つで、c を使用します。rawWeb ページをインデックス化するための SeekportBot ler。 残念ながら、それは時々それを過度に使用し、不要なトラフィックを作成します.
キュプリン
SeekportBot とは何ですか?
SeekportBot あります web crawler 同社が開発した Seekport、ドイツに拠点を置いています (ただし、フィンランドを含むいくつかの国の IP を使用しています)。 このボットは、検索エンジンの結果に表示できるように、Web サイトをクロールしてインデックスを作成するために使用されます。 Seekport. 私が知る限り、機能しない検索エンジンです。 少なくとも、どのキー フレーズについても結果は返されませんでした。
SeekportBot 用途 user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"SeekportBot やその他の c へのアクセスをブロックする方法rawウェブサイトをクリックした
このWebスパイダーまたは別のWebスパイダーがWebサイト全体をスキャンしてWebサーバーへの不要なトラフィックを作成する必要がないという結論に達した場合、それらのアクセスをブロックできるいくつかの方法があります.
Web サーバー レベルのファイアウォール
それらはファイアウォール アプリケーションです。 open-source オペレーティングシステムにインストールできる Linux また、いくつかの基準に基づいてトラフィックをブロックするように構成できます。 IP アドレス、場所、ポート、プロトコル、またはユーザー エージェント。
APF (Advanced Policy Firewall) サーバーレベルで不要なボットをブロックできるソフトウェアです。
SeekportBot やその他の Web スパイダーは複数の IP ブロックを使用するため、最も効果的なブロック ルールは "user agent"。 したがって、アクセスをブロックしたい場合は SeekportBot によります APFを介して Web サーバーに接続するだけです。 SSHをクリックし、構成ファイルにフィルター規則を追加します。
1. で設定ファイルを開きます nano (または別の発行者)。
sudo nano /etc/apf/conf.apf2.「」で始まる行を探しますIG_TCP_CPORTS」を入力し、ブロックするユーザー エージェントをこの行の最後に追加し、その後にコンマを追加します。 たとえば、ブロックしたい場合 user agent 「SeekportBot"、行は次のようになります。
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. ファイルを保存し、APF サービスを再起動します。
sudo systemctl restart apf.service「SeekportBot」アクセスはブロックされます。
フィルタ web crawls Cloudflare の助けを借りて – SeekportBot のアクセスをブロックする
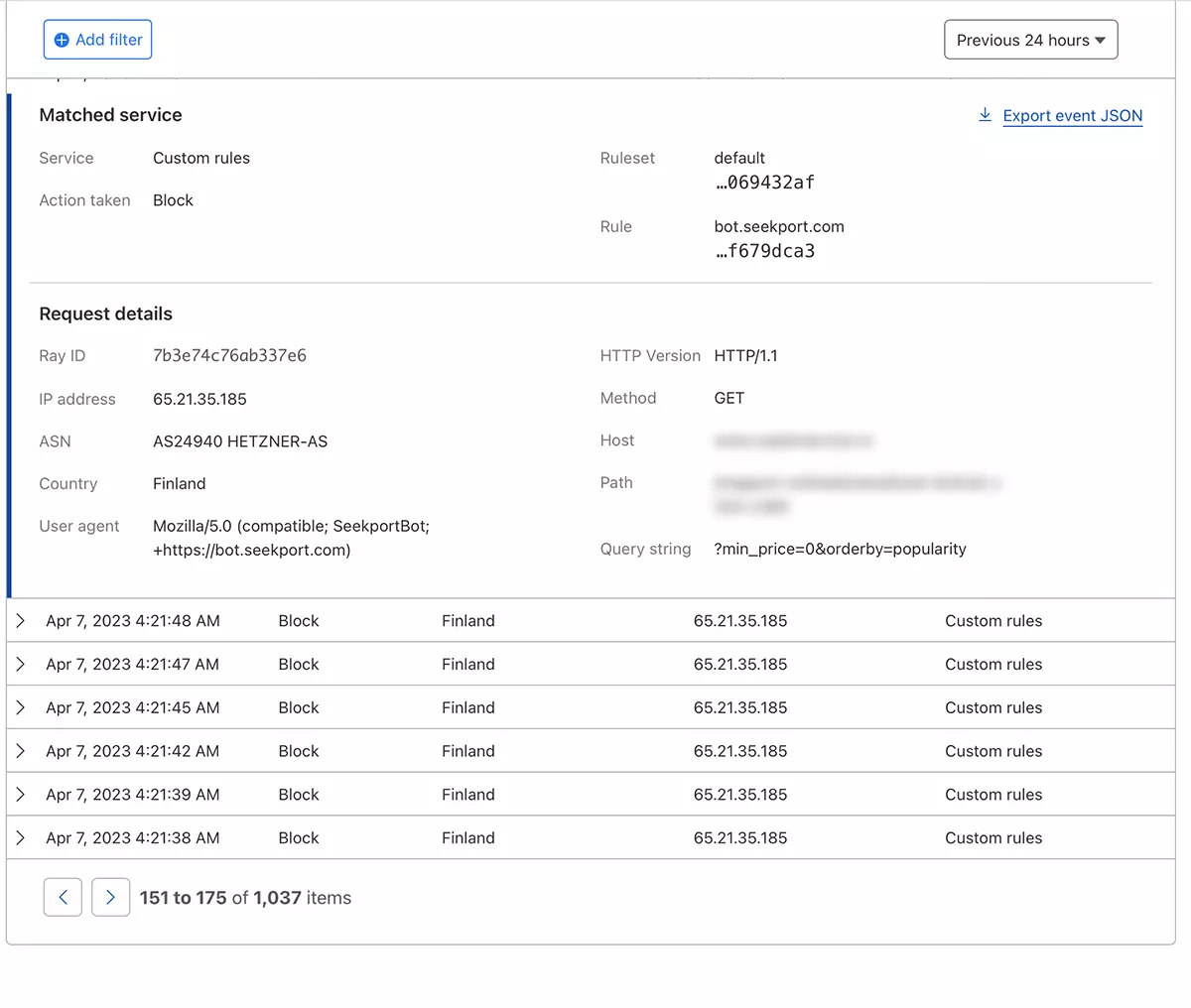
Cloudflare の助けを借りて、ボットによる Web サイトへのアクセスをさまざまな方法で制限できる最も安全で便利な方法のように思えます。 ケースでも使用した方法 SeekportBot オンラインストアへのトラフィックをフィルタリングします。
ウェブサイトが Cloudflare に追加されており、DNS サービスが有効になっている (つまり、ウェブサイトへのトラフィックが Cloudflare を通過する) と仮定して、以下の手順に従います。
1. Clouflare アカウントを開き、アクセスを制限したい Web サイトにアクセスします。
2. 次の場所に移動します。 Security → WAF 新しいルールを追加します。 Create rule.
3. 新しいルールの名前を選択します。 Field: User Agent – Operator: Contains – Value: SeekportBot (または他のボット名) – Choose action: Block – Deploy.
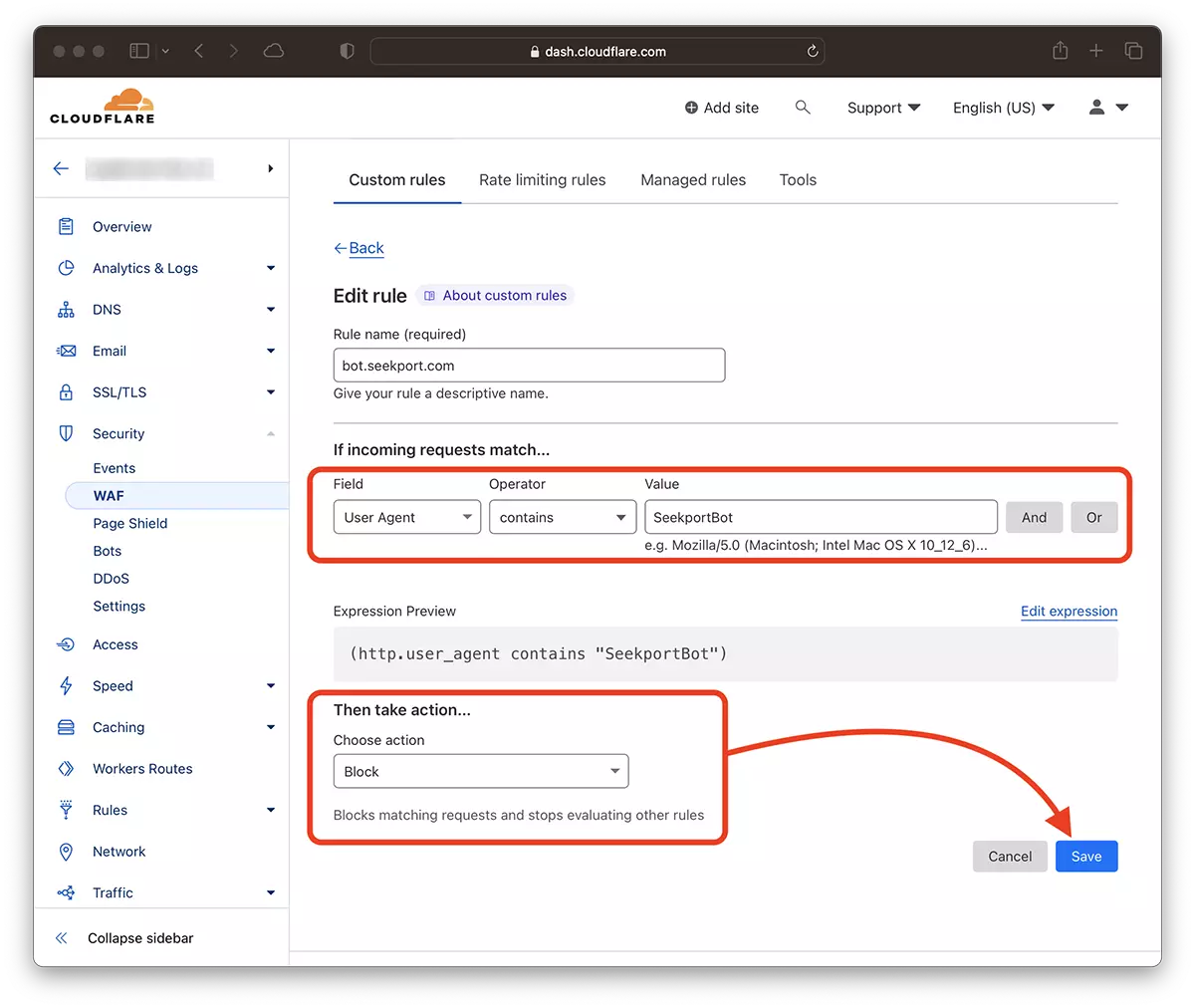
ほんの数秒で、新しいルール WAF (Web Application Firewall) 効き始めます。
理論的には、Web スパイダーがサイトにアクセスする頻度は次のように設定できます。 robots.txt、しかし...それは理論上だけです。
User-agent: SeekportBot
Crawl-delay: 4多くの web crawlerii (Bing と Google を除く) はこれらの規則に従っていません。
結論として、Web c を識別する場合rawl サイトに過度にアクセスする人は、アクセスを完全にブロックするのが最善です。 もちろん、このボットがあなたが興味を持っている検索エンジンからのものではない場合.