WordPressとTumblrの背後にあるAutomatticは、MidJourneyやOpenAIを含む人工知能企業にデータを販売して、ユーザーのコンテンツを収益化するための議論を計画しています。これらのTumblrとWordPress.comのブログプラットフォームのデータは、AIモデルのトレーニングに使用されます。
取引の詳細はまだ明確ではありませんが、このニュースは、両プラットフォームでのプライベートコンテンツの潜在的な不適切な使用に関するユーザーの懸念を引き起こしました。また、404 Mediaによれば、Automattic内での内部的な対立が生じている可能性があります。収集されたコンテンツには、会社内で保持されるべきでないプライベートデータが含まれているためです。
否定的な反応に対応して、Automatticは、ユーザーがAIのトレーニングにデータを共有しないように選択できる新機能を導入する予定です。同社はブログで、TumblrとWordPressのユーザーに対してより大きなコントロールを提供することにコミットしており、AI企業による探索を阻止するための設定の導入を言及しています。
ブログコンテンツの利用に関する問題は、AIモデルを開発する企業によって行われるプラットフォームに限られるものではありません。OpenAIやGoogleの両社が、ウェブサイト全体から情報を収集するクローラーと呼ばれるロボットを使用して、人工知能モデルのトレーニングを行っています。このプロセスは、検索エンジンによるデータ収集と類似しています。
ブログの所有者がOpenAIやGemini(Bard)によるデータ取得を防止する方法は?
ブログまたはウェブサイトの所有者で、OpenAIやGemini(Bard)によるAIモデルのトレーニングにデータを使用されたくない場合は、ロボット(クローラー)のコンテンツへのアクセスをブロックすることができます。この制限は、robots.txtファイルを介して実装できます。
OpenAI Crawlers
User-agent: GPTBot
Disallow: /Gemini Crawlers
User-agent: Google-Extended
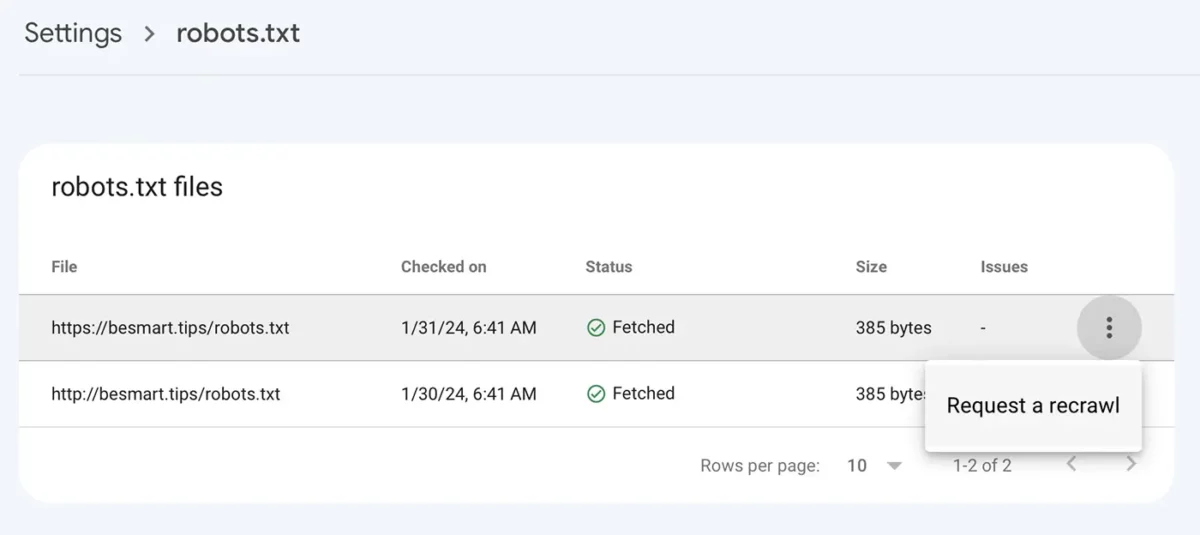
Disallow: /新しい行を含むrobots.txtファイルを保存した後は、Googleコンソールに移動して、設定 > robots.txt > XNUMXつの点のメニューをクリックし、「再クロールをリクエスト」をクリックします。
関連する GPT-5 と OpenAI によって開発された新しいウェブクローラー GPTBot。
TumblrとWordPressのユーザーにとって、OpenAIや他の人工知能開発企業によるブログからのデータ取得へのアクセスは、Automatticが提供するツールを使用してブロックできます。